
python爬虫最新微博评论爬取方法(非url中拼接page=方法)
今天一友叫我帮忙改微博评论爬虫代码!直接上代码
import requests
import json
url_comment = ['http://m.weibo.cn/api/comments/show?id=4464214141527990&page={}'.format(str(i)) for i in range(0,10)]
def get_comment(url):
wb_data = requests.get(url).text
data_comment = json.loads(wb_data)
try:
datas = data_comment['data']
for data in datas:
print(data.get("text"))
with open('评论.txt', 'a', encoding='utf-8') as f:
f.writelines(comment + '\n')
except KeyError:
pass
for url in url_comment:
get_comment(url)好像什么毛病就是有看着点乱 运行不报错无文档,本着实践出真理的出发点,小试牛刀看看问题所在这种for循环写法我还真的不喜欢,我喜欢遍历数组,直接上手
①先检查API的可用性
②检查json数据解析是否正确
③改for循环为遍历数组方式
上图改后代码
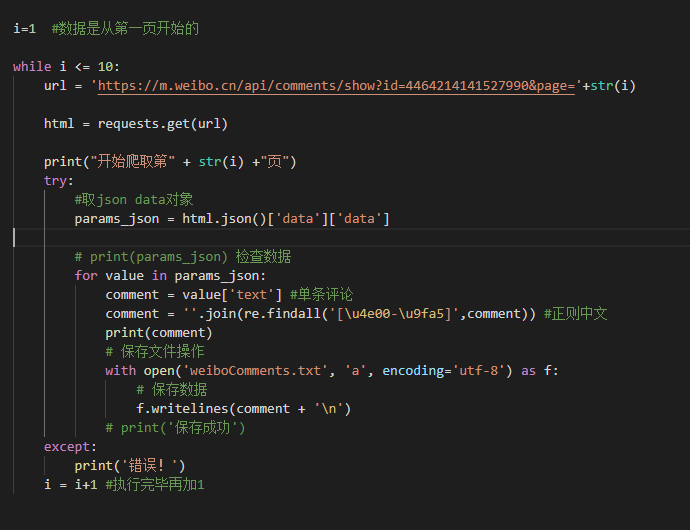
按照个人喜欢的方法来写的。。。。
py weiboComments.py 运行没毛病 于是欢快的跑着代码,

但是到第三页开始报错
直接访问API https://m.weibo.cn/api/comments/show?id=4180274512614207&page=3 一探究竟
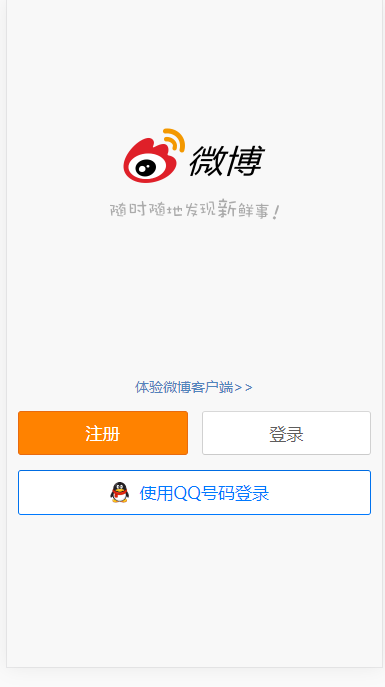
emmm居然还要登录 那就登录吧
根据以往的经验看请求头的cookie加入到requests header能不能行
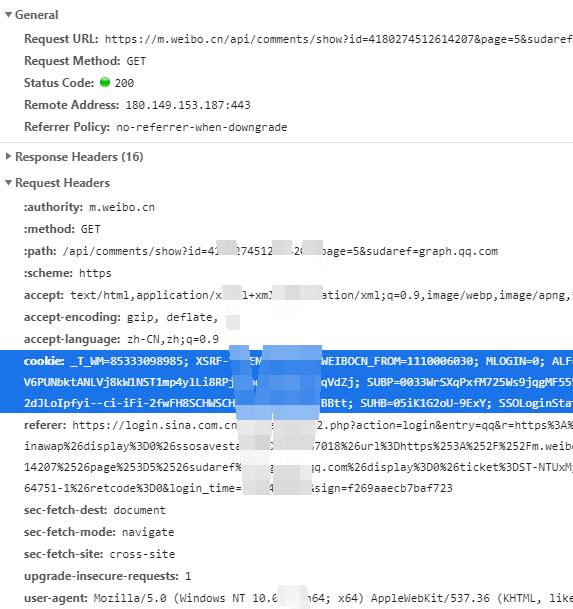
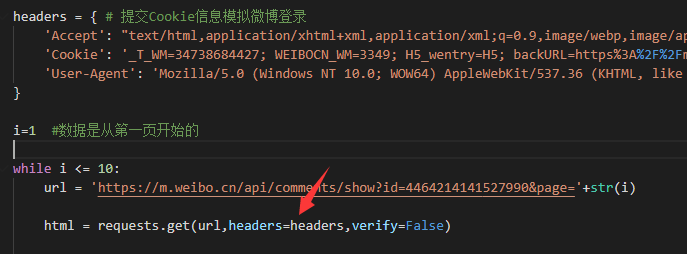
加入heaser “verify=False”忽略证书

顺利通过啊 真好!满满的成就感 跑了几页想打开看看 这个微博评论有多少想着能不能全爬下来结果又发现新问题了评论不能对上
https://m.weibo.cn/api/comments/show?id=4180274512614207&page=1
https://m.weibo.cn/detail/4464214141527990
id是一样的 评论不能对上 好家伙这么久白搞了
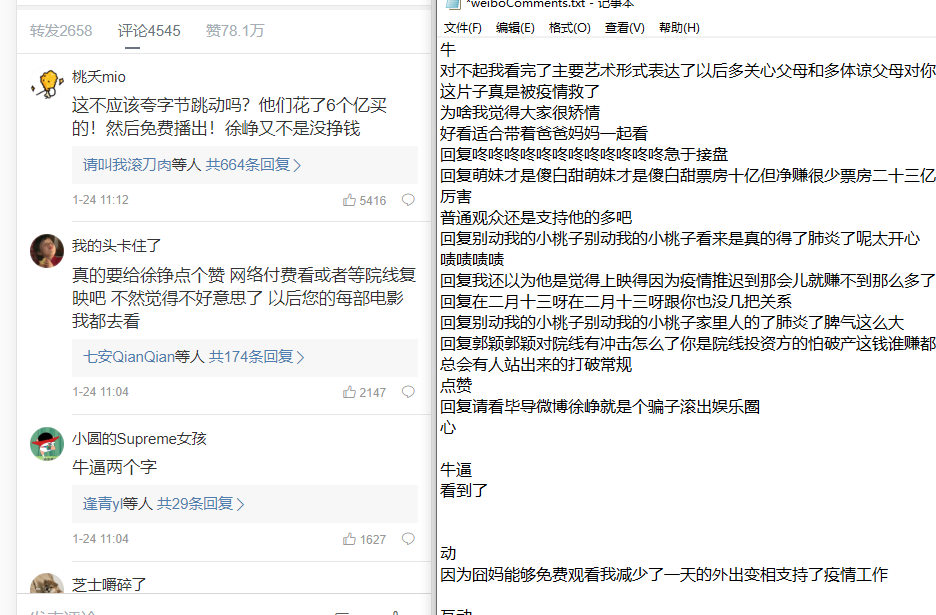
那就只能自己抓包了 F12 刷新网页 查看network
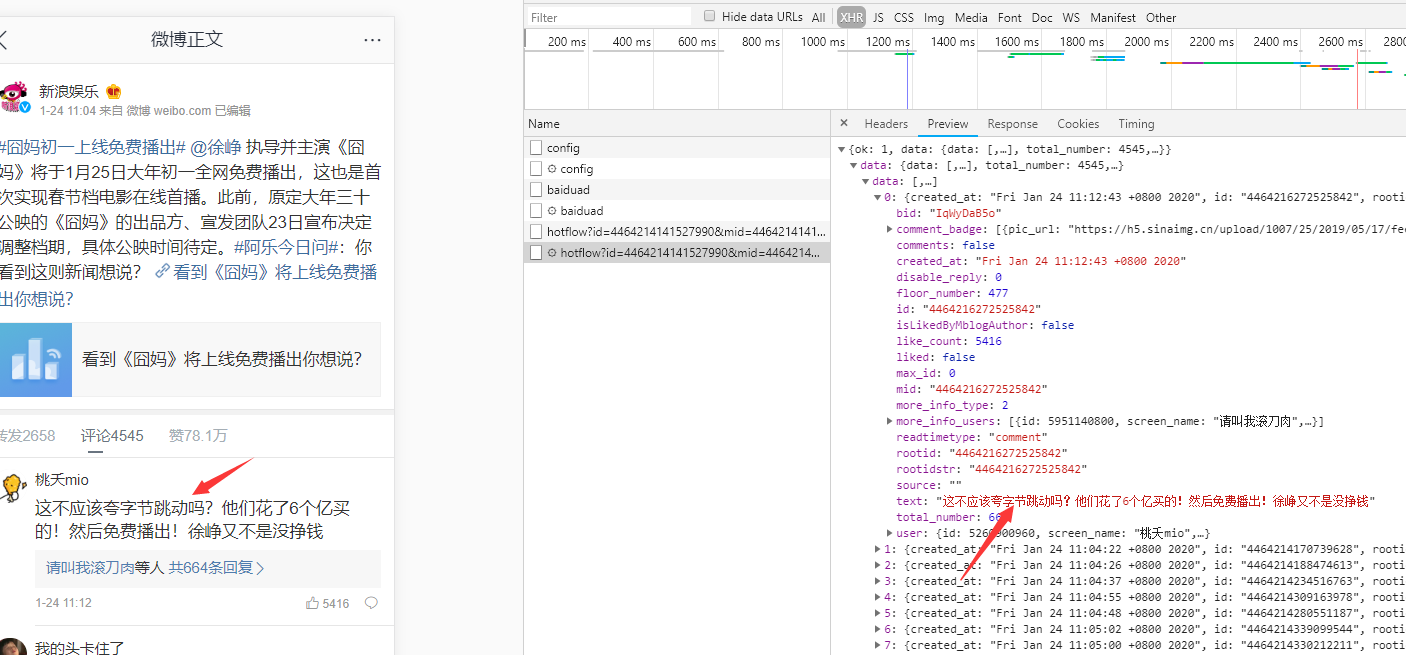
很好数据没有加密
https://m.weibo.cn/comments/hotflow?id=4464214141527990&mid=4464214141527990&max_id_type=0
仔细看没有page 还有两个新字段,mid、max_id_type。
继续下一个url 又多一个 max_id
我想应该max_id就是加密的page吧 找一找max_id怎么来的 撒网式的搜索 max_id 源码 js post/get参数 response
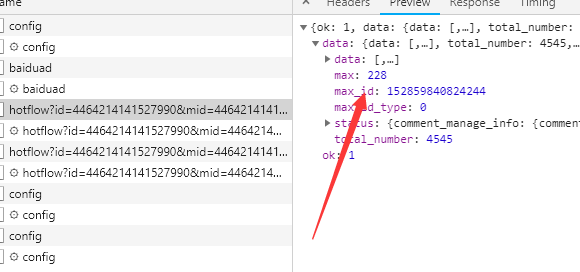
就在上一个url response里面 第一页的url上不带有max_id字段,其他的请求发起时候时,有上次请求response中返回的max_id数据
api分析完毕那就愉快的撸代码吧 改一改
import requests
import re
import time
headers = { # 提交Cookie信息模拟微博登录
'Accept': "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8",
'Cookie': '_T_WM=34738684427; WEIBOCN_WM=3349; H5_wentry=H5; backURL=https%3A%2F%2Fm.weibo.cn%2Fapi%2Fcomments%2Fshow%3Fid%3D4180274512614207%26page%3D3; ALF=1594995680; SUB=_2A25z7laxDeRhGeNL6lAW8izKyjiIHXVREXr5rDV6PUNbktANLXn6kW1NST1mpx09_xz6rcfp82EI3pIdjEEZWlU0; SUBP=0033WrSXqPxfM725Ws9jqgMF55529P9D9W5rl.wny_7w0UmCzp64LHxJ5JpX5KzhUgL.Fo-feKzNeozceKB2dJLoIpfyi--ci-iFi-2fwFH8SCHWSCHFxFH8SFHFBCHFBBtt; SUHB=0WGsg7-2qWhBx_; SSOLoginState=1592403681; MLOGIN=1; WEIBOCN_FROM=1110006030; XSRF-TOKEN=d3f5cf; M_WEIBOCN_PARAMS=oid%3D4464214141527990%26luicode%3D20000061%26lfid%3D4464214141527990',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36',
}
i=1 #数据是从第一页开始的
max_id = '' # 第一次是没有的后面都需要这个变量访问
while i <= 10:
# url = 'https://m.weibo.cn/api/comments/show?id=4464214141527990&page='+str(i)
if i == 1:
url = 'https://m.weibo.cn/comments/hotflow?id=4464214141527990&mid=4464214141527990&max_id_type=0'
else:
url = 'https://m.weibo.cn/comments/hotflow?id=4464214141527990&mid=4464214141527990&max_id='+str(max_id)+'&max_id_type=0'
html = requests.get(url,headers=headers,verify=False)
print("开始爬取第" + str(i) +"页")
try:
#取json data对象
params_json = html.json()['data']['data']
#解析max_id
max_id = html.json()['data']['max_id']
print(max_id)
# print(params_json) 检查数据
for value in params_json:
comment = value['text'] #单条评论
comment = ''.join(re.findall('[\u4e00-\u9fa5]',comment)) #正则中文
print(comment)
# 保存文件操作
with open('weiboComments.txt', 'a', encoding='utf-8') as f:
# 保存数据
f.writelines(comment + '\n')
# print('保存成功')
except:
print('错误!')
i = i+1 #执行完毕再加1
print("5s后开始下一页")
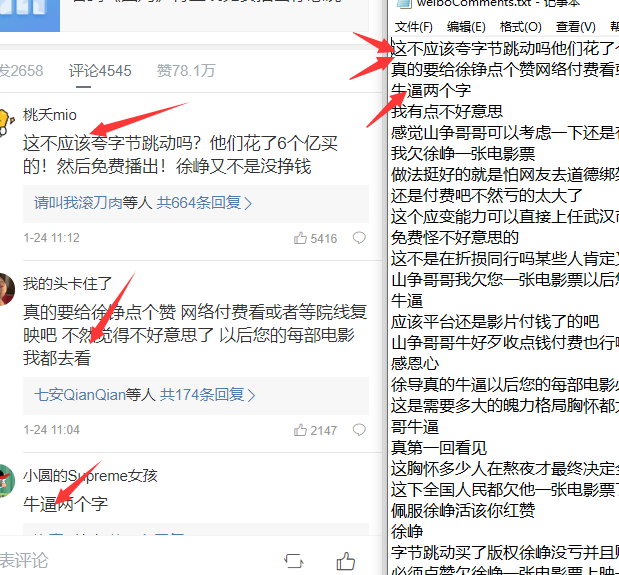
time.sleep(5) #爬取一页后延时爬取 防止触发反爬程序由于只是一个demo我就不封装函数了 就这样吧能跑就行
 蜀ICP备2021011288号-5
蜀ICP备2021011288号-5